你好,我是 Yaxin Luo。
关于我
Decorative animated background
我是 Yaxin Luo,目前是 MBZUAI 机器学习方向一年级博士生,导师是 Prof. Zhiqiang Shen。我也与好友 Xiaofu Chen 保持紧密合作。 我的研究关注 原生多模态基础模型(Native Multimodal Foundation Models)与多模态智能体模型(Multimodal Agentic Models),尤其希望探索模型如何在统一框架中完成跨模态的理解、生成、推理、规划与行动。
在攻读博士之前,我本科毕业于 Technical University of Denmark,曾受 Prof. Dim P. Papadopoulos 指导。本科期间,我也与 Dr. Gen Luo 和 Prof. Rongrong Ji 合作开展高效深度学习相关研究。这些经历让我持续关注高效、可扩展,并且能够服务真实世界任务的智能系统。
我的研究兴趣主要集中在:
- 原生多模态基础模型与多模态智能体模型:我将这两个方向视为高度耦合的研究问题。一方面,原生多模态基础模型需要在视觉、语言、交互状态等信息之间建立统一表征,支持多模态理解与生成、跨模态迁移以及更强的多模态推理能力;另一方面,多模态智能体模型进一步要求模型具备面向复杂长程任务的规划、记忆、执行与自我修正能力。我的长期目标是构建能够在开放任务中持续理解环境、生成方案、推理决策并采取行动的多模态智能系统,具体关注方向包括 Agentic Design、Agentic Game Crafting 和 Application Crafting。
最近,我主要关注面向长程交互任务的多模态智能体基础模型与系统,尤其是 Agentic Design、Agentic Game Crafting 和 Application Crafting。
经历

Research Intern, Meituan LongCat Team
参与 Unified Multimodal Foundation Model Projects (LongCat-Next Team)。
- 面向统一多模态模型的长程多模态交互任务:Agentic Design System。
- 面向理解与生成统一建模的离散视觉编码器。

Research Assistant, MBZUAI
在 VILA Lab 由 Prof. Zhiqiang Shen 指导。
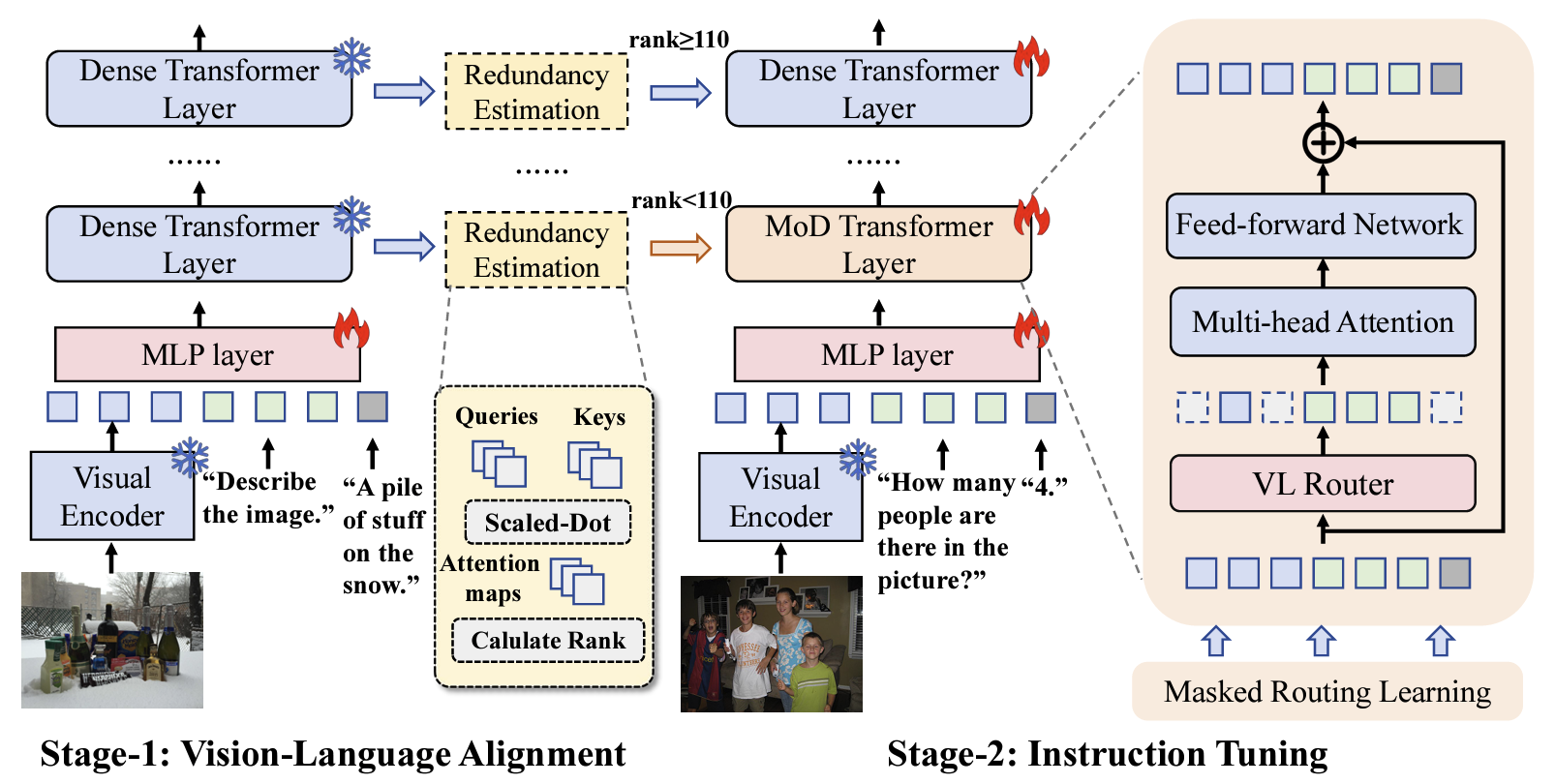
- 研究 language-pretraining-induced bias 如何作为通用视觉任务的强先验,展示 LLM 先验向纯视觉学习迁移的可能性,该工作发表于 TMLR 2026。
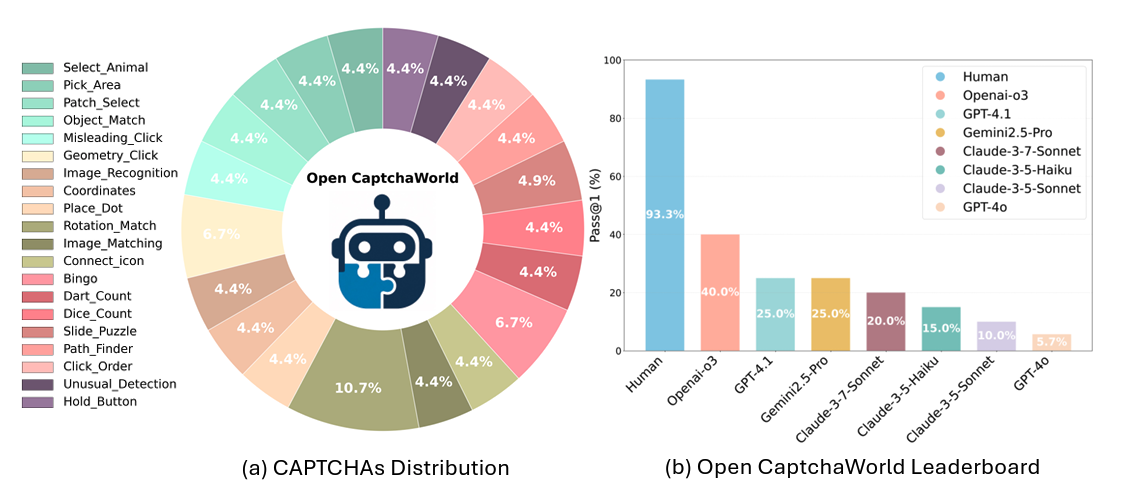
- 探索多模态大语言模型(MLLMs)中的推理与智能体行为,主导 OpenCaptchaWorld benchmark(NeurIPS 2025)。
最新动态
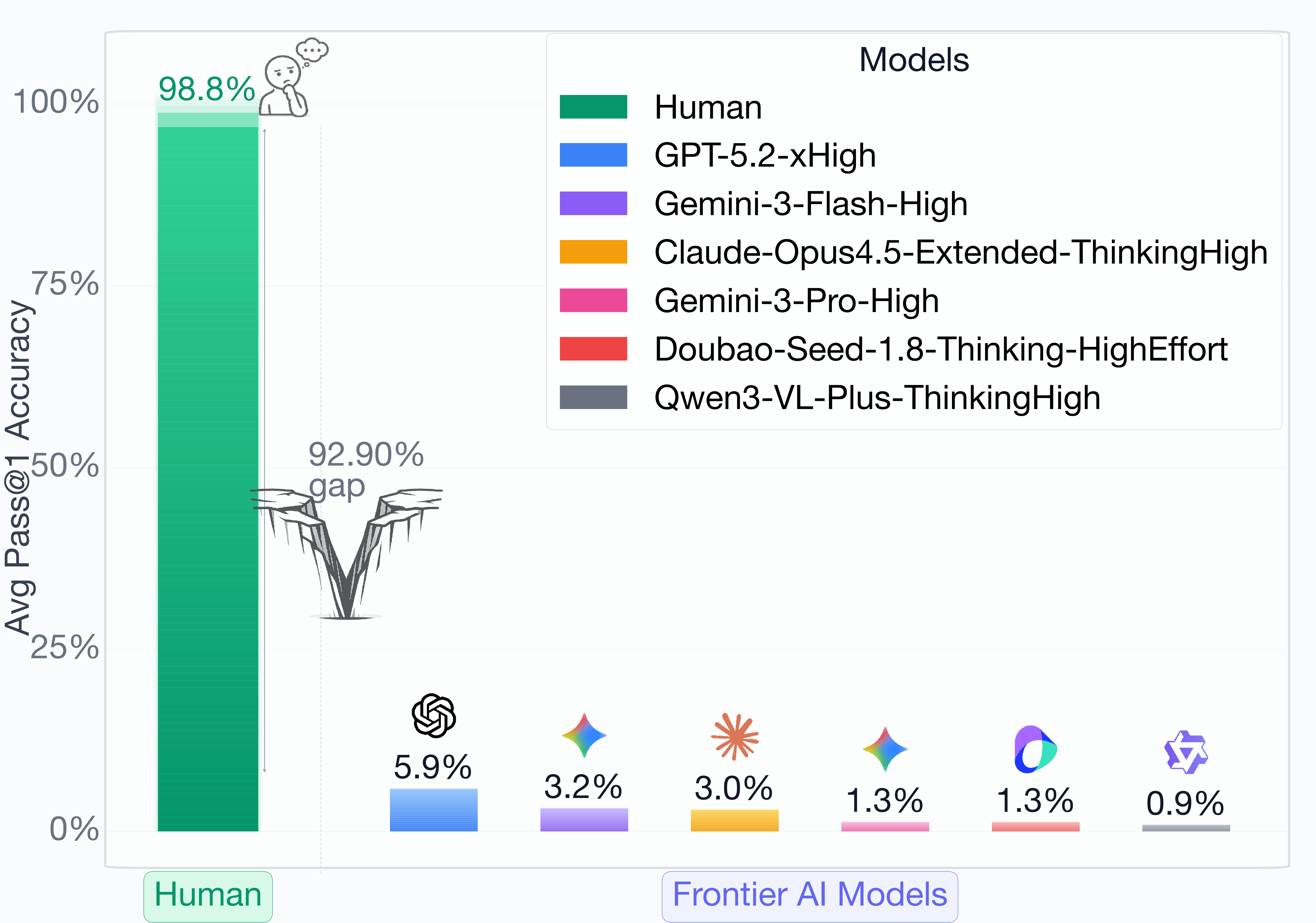
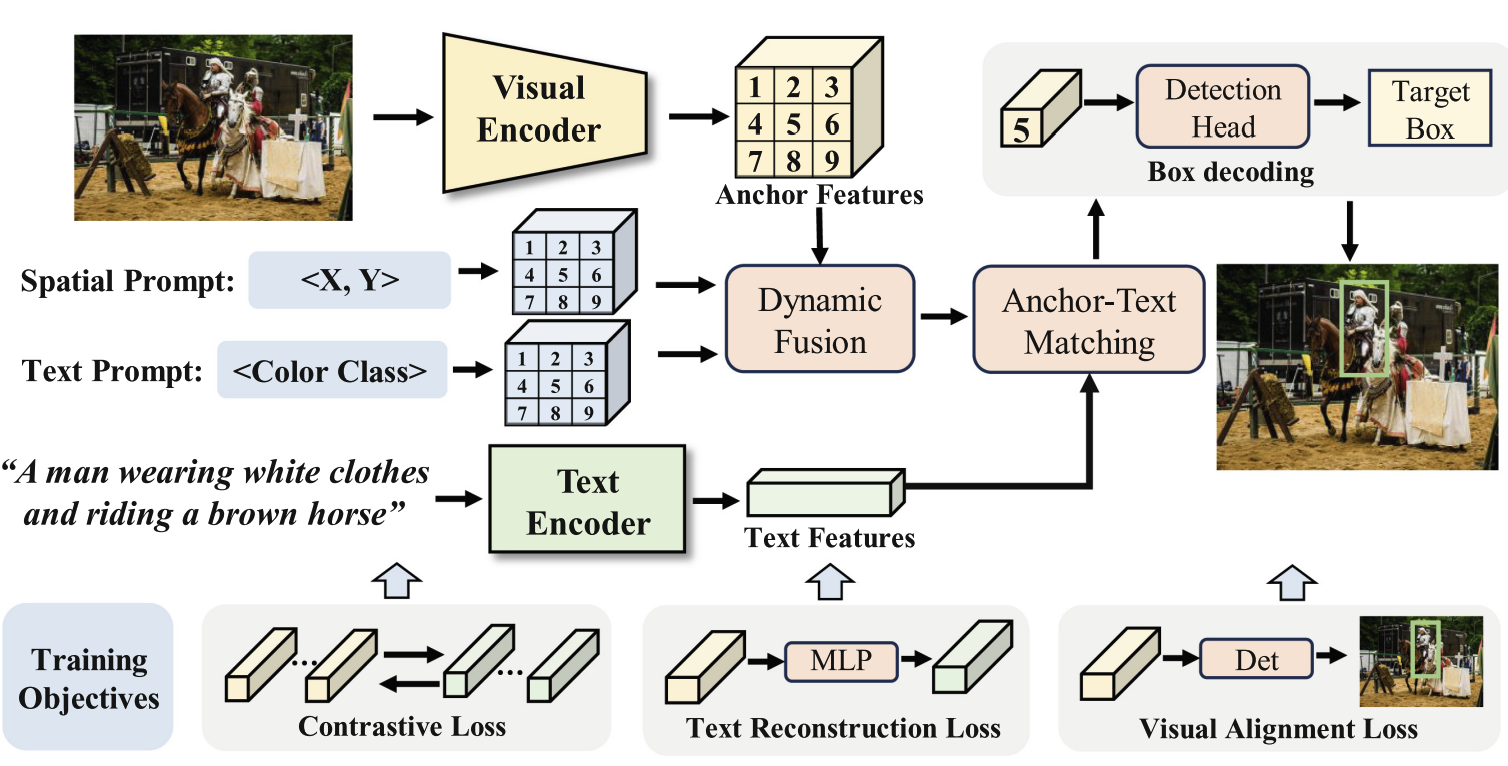
[2026-02-10] Next-Gen CAPTCHAs 已上线 arXiv。这是一套利用认知差异构建可扩展、多样化 GUI-Agent 防御任务的框架。
[2025-09-18] OpenCaptchaWorld 被 NeurIPS 2025 接收。
代表论文
(* 表示共同一作)
完整且最新的论文列表请参考我的 Google Scholar 主页。