Hi there! 👋 I am Yaxin Luo.
About Me
Decorative animated background 

Hello! I am a First-Year Machine Learning PhD student at MBZUAI, advised by Prof. Zhiqiang Shen. I am also closely working with my friend Xiaofu Chen. Currently, my research explores Native Multimodal Foundation Models and Multimodal Agentic Models as tightly coupled directions: building models that unify understanding, generation, reasoning, planning, and action across diverse modalities, and using those capabilities to support long-horizon interactive tasks.
Previously, I earned my Bachelor’s degree from Technical University of Denmark, where I was fortunate to be supervised by Prof. Dim P. Papadopoulos. Meanwhile, I was lucky to be collaborating with Dr.Gen Luo and Prof.Rongrong Ji on efficient deep learning research during my bachelor.
More about my earlier journey...
I spent an intense and rewarding year at the University of Edinburgh studying pure mathematics and physics—an experience that sparked my passion for science and technology, deepened my curiosity about the unknown, I was curious and wanted to explore String Theory at that time, this one year ultimately shaped who I am today. Before Edinburgh, while enrolled in a Bio-Medicine program at the University of Queensland and preparing for the UCAT test to be admitted into the university's medical school, I failed at the end. As I only focused on managing a high-street multi-brand boutique which was located in Brisbane's Southbank near the casino, and was far more focused on business than on study and research; that Edinburgh year changed my priorities and set me on a research path, thanks to the advice, encouragement and support of my academic personal tutor Prof.Ana Rita Pires when I was at Edinburgh. Anyway, all those past experiences have made me who I am today.
My research interests focus on:
- Native Multimodal Foundation Models and Multimodal Agentic Models : I view native multimodal foundation models and multimodal agentic models as a connected research agenda. Native multimodal foundation models provide unified representations and capabilities for multimodal understanding, generation, reasoning, planning, and action; multimodal agentic models further test and extend these capabilities through long-horizon interaction, memory, execution, and self-correction. I am especially interested in concrete long-horizon tasks such as Agentic Design, Agentic Game Crafting, and Application Crafting.
Recently, I am focusing on long-horizon multimodal agentic foundation models and systems, especially for Agentic Design, Agentic Game Crafting, and Application Crafting.
Experience
Research Intern, Meituan LongCat Team
Working on Unified Multimodal Foundation Model Projects(LongCat-Next Team).
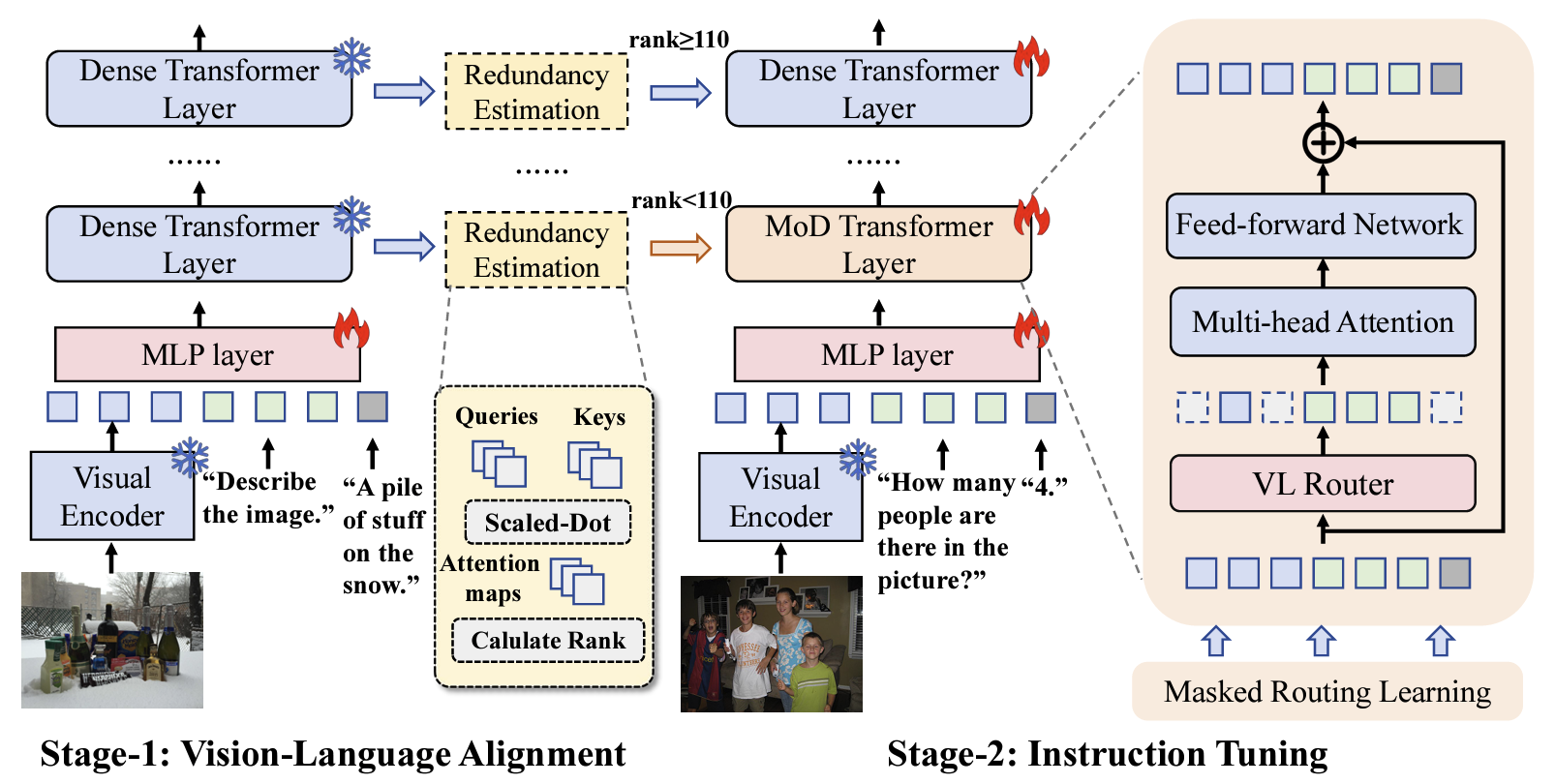
- Long-Horizon Multimodal Interactive Tasks for Unified Multimodal Models: Agentic Design System.
- Unified Discrete Vision Encoder for both understanding and generation.
Research Assistant, MBZUAI
Advised by Prof. Zhiqiang Shen at the VILA Lab.
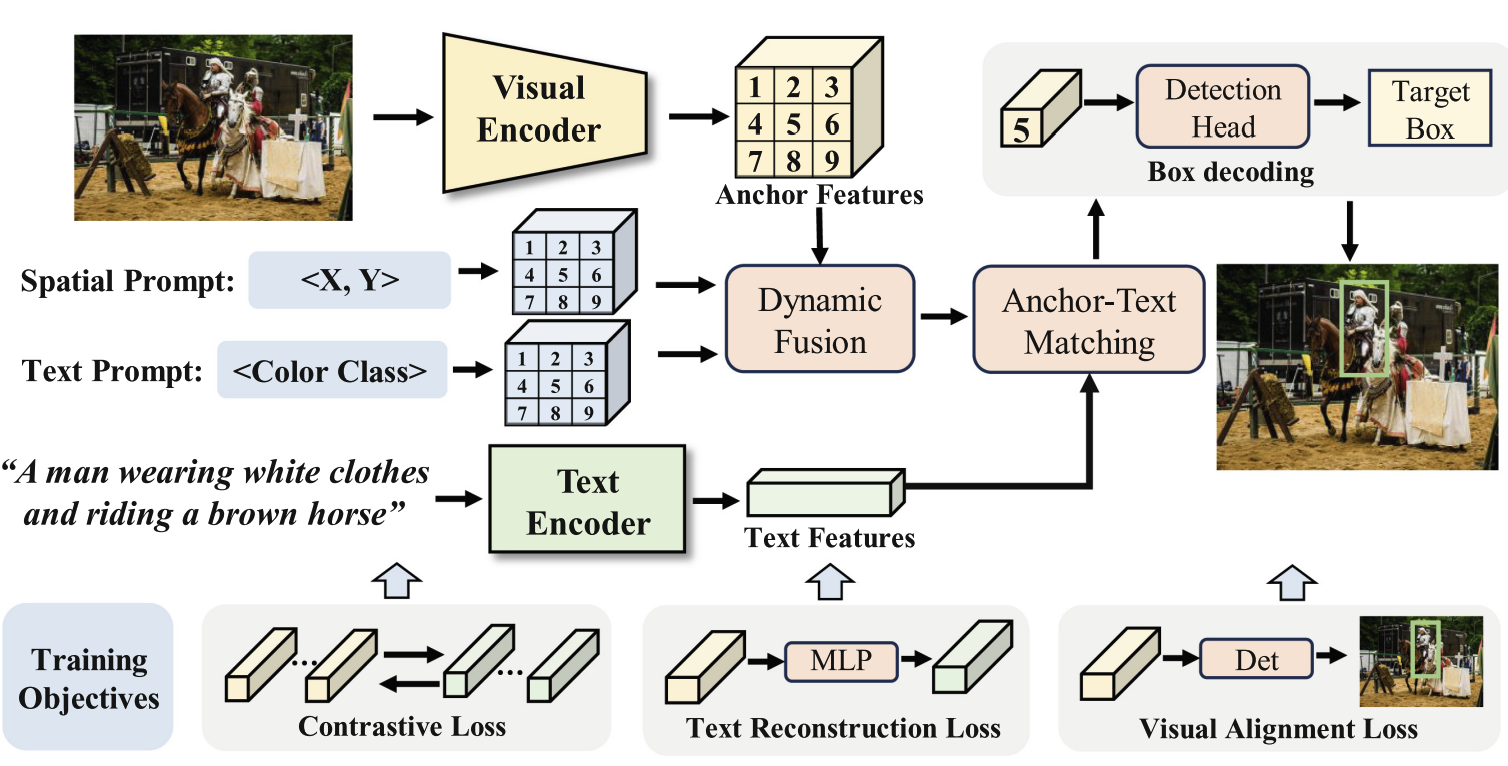
- Investigated language-pretraining-induced bias as a strong foundation for general vision tasks, showing LLM priors transfer to pure-vision learning — published in TMLR 2026.
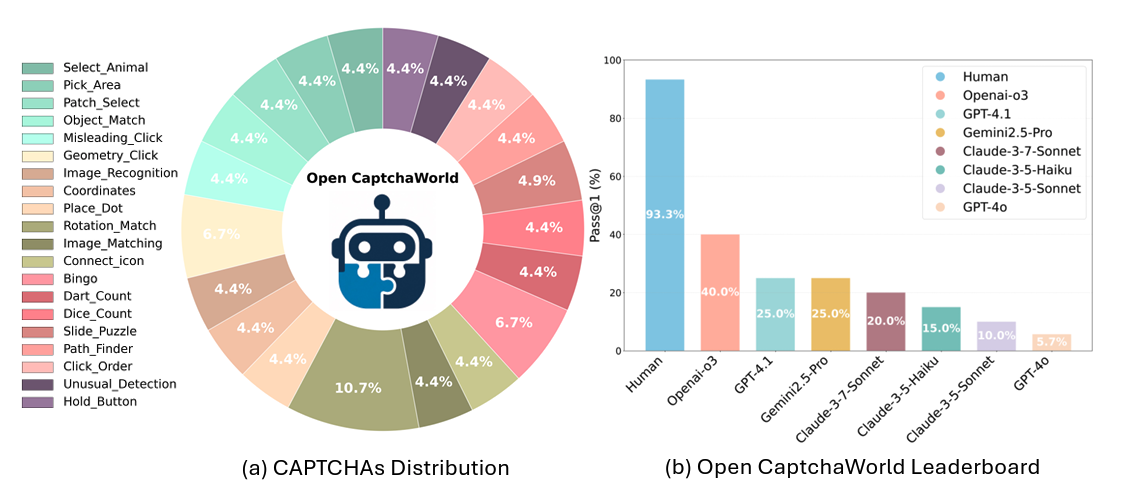
- Explored reasoning and agentic behaviors in multimodal large language models (MLLMs), leading the OpenCaptchaWorld benchmark (NeurIPS 2025).
News
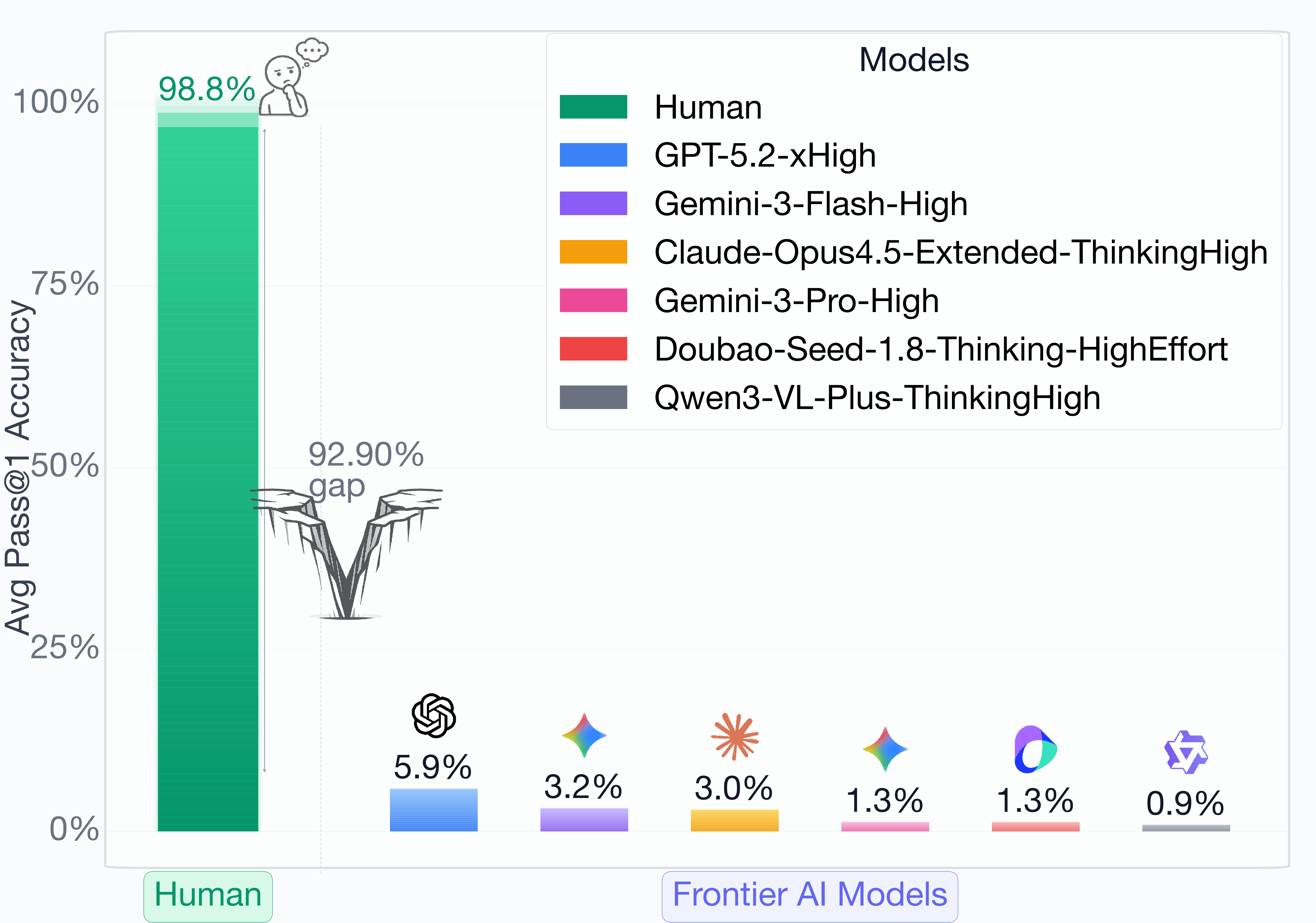
[2026-02-10] 🚀 Next-Gen CAPTCHAs is now available on arXiv! A defense framework leveraging cognitive gaps against MLLM-based GUI agents.
[2025-09-18] 🚀 OpenCaptchaWorld has been accepted by NeurIPS 2025.
Selected Publications
( * indicate equal contribution)
For full and up-to-date publication list, please refer to my Google Scholar page.